.")
Hi! My name is Jieyong Kim, an M.S. student at the Graduate School of Artificial Intelligence, Yonsei University. I am advised by Prof. Dongha Lee in the Data & Language Intelligence Lab.
My research explores how to extract meaningful insights from data and maximize their utility through the integration of AI. I am particularly interested in adapting and personalizing large language models (LLMs) to build systems that can effectively operate in real-world scenarios. By aligning AI behavior with user intent and contextual needs, my work aims to make AI systems more practical, adaptive, and impactful in everyday applications.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Yonsei UniversityM.S. in Artificial IntelligenceSep. 2024 - present
Yonsei UniversityM.S. in Artificial IntelligenceSep. 2024 - present -
Yonsei UniversityB.S. in Computer ScienceMar. 2019 - Sep. 2024
Experience
-
DLI Lab, Yonsei UniversityResearch InternMar. 2023 - Sep. 2024
-
 Republic of Korea ArmyDischarged due to injury during training (Private First Class)Apr. 2021 - Dec. 2021
Republic of Korea ArmyDischarged due to injury during training (Private First Class)Apr. 2021 - Dec. 2021 -
Computer Science Student Council, Yonsei UniversityVice PresidentMar. 2020 - Feb. 2021
-
Computer Science Student Council, Yonsei UniversityFreshman Class RepresentativeMar. 2019 - Feb. 2020
News
Selected Publications (view all )

IPQA: A Benchmark for Core Intent Identification in Personalized Question Answering
Jieyong Kim, Maryam Amirizaniani, Soojin Yoon, Dongha Lee# (# corresponding author)
Under review 2025
Intent identification serves as the foundation for generating appropriate responses in personalized question answering (PQA). However, existing benchmarks evaluate only response quality or retrieval performance without directly measuring intent identification capabilities. This gap is critical because without understanding which intents users prioritize, systems cannot generate responses satisfying individual information needs. To address this, we introduce the concept of \textit{core intents}: intents users prioritize when selecting answers to satisfy their information needs. To evaluate these core intents, we propose IPQA, a benchmark for core Intent identification in Personalized Question Answering. Since users do not explicitly state their prioritized intents, we derive core intents from observable behavior patterns in answer selection, grounded in satisficing theory where users choose answers meeting their acceptance thresholds. We construct a dataset with various domains through systematic filtering, LLM-based annotation, and rigorous quality control combining automated verification with human validation. Experimental evaluations across state-of-the-art language models reveal that current systems struggle with core intent identification in personalized contexts. Models fail to identify core intents from user histories, with performance degrading as question complexity increases.
IPQA: A Benchmark for Core Intent Identification in Personalized Question Answering
Jieyong Kim, Maryam Amirizaniani, Soojin Yoon, Dongha Lee# (# corresponding author)
Under review 2025
Intent identification serves as the foundation for generating appropriate responses in personalized question answering (PQA). However, existing benchmarks evaluate only response quality or retrieval performance without directly measuring intent identification capabilities. This gap is critical because without understanding which intents users prioritize, systems cannot generate responses satisfying individual information needs. To address this, we introduce the concept of \textit{core intents}: intents users prioritize when selecting answers to satisfy their information needs. To evaluate these core intents, we propose IPQA, a benchmark for core Intent identification in Personalized Question Answering. Since users do not explicitly state their prioritized intents, we derive core intents from observable behavior patterns in answer selection, grounded in satisficing theory where users choose answers meeting their acceptance thresholds. We construct a dataset with various domains through systematic filtering, LLM-based annotation, and rigorous quality control combining automated verification with human validation. Experimental evaluations across state-of-the-art language models reveal that current systems struggle with core intent identification in personalized contexts. Models fail to identify core intents from user histories, with performance degrading as question complexity increases.
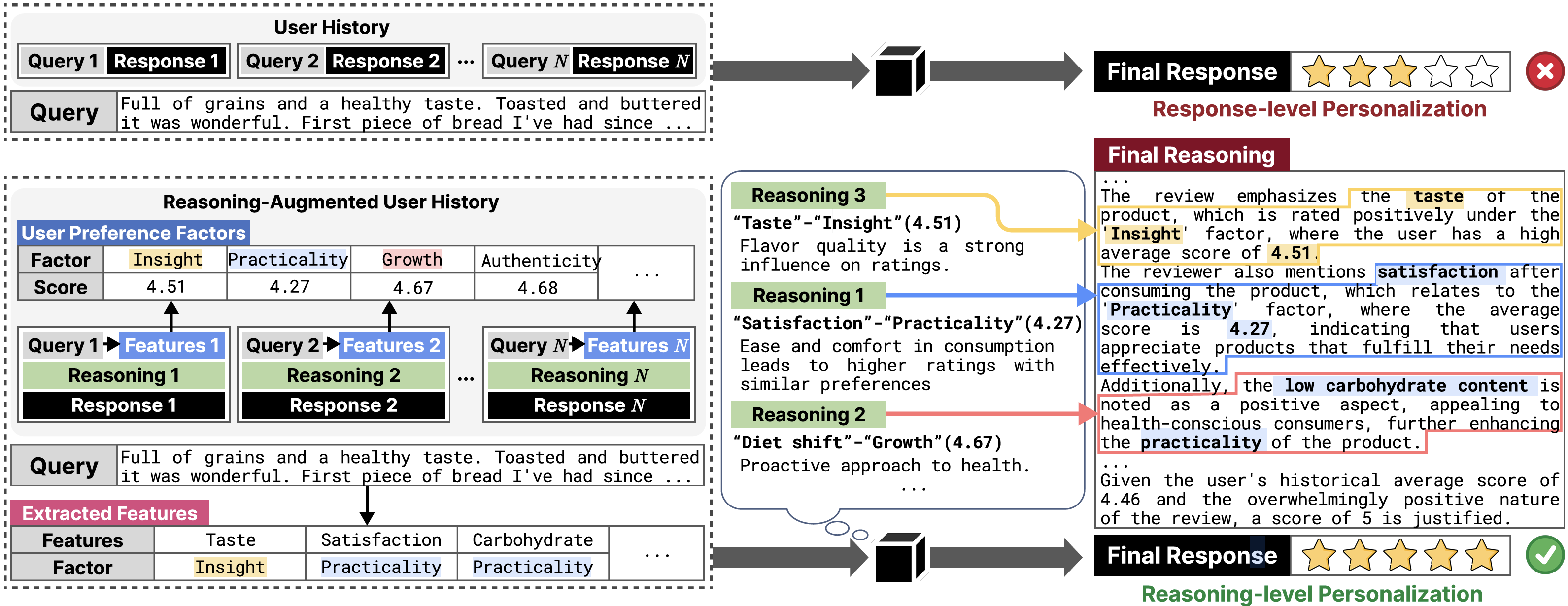
RPM: Reasoning-Level Personalization for Black-Box Large Language Models
Jieyong Kim*, Tongyoung Kim*, Soojin Yoon, Jaehyung Kim, Dongha Lee# (* equal contribution, # corresponding author)
International Conference on Learning Representations (ICLR) 2026
Large language models (LLMs) have recently achieved impressive performance across a wide range of natural language tasks and are now widely used in real-world applications. Among them, black-box LLMs--served via APIs without access to model internals--are especially dominant due to their scalability and ease of deployment. Despite their strong capabilities, these models typically produce generalized responses that overlook personal preferences and reasoning styles. This has led to growing interest in black-box LLM personalization, which aims to tailor model outputs to user-specific context without modifying model parameters. However, existing approaches primarily focus on response-level personalization, attempting to match final outputs without modeling personal thought process. To address this limitation, we propose RPM, a framework for reasoning-level personalization that aligns the model's reasoning process with a user's personalized logic. RPM first constructs statistical user-specific factors by extracting and grouping response-influential features from user history. It then builds personalized reasoning paths that reflect how these factors are used in context. In the inference stage, RPM retrieves reasoning-aligned examples for new queries via feature-level similarity and performs inference conditioned on the structured factors and retrieved reasoning paths, enabling the model to follow user-specific reasoning trajectories. This reasoning-level personalization enhances both predictive accuracy and interpretability by grounding model outputs in user-specific logic through structured information. Extensive experiments across diverse tasks show that RPM consistently outperforms response-level personalization methods, demonstrating the effectiveness of reasoning-level personalization in black-box LLMs.
RPM: Reasoning-Level Personalization for Black-Box Large Language Models
Jieyong Kim*, Tongyoung Kim*, Soojin Yoon, Jaehyung Kim, Dongha Lee# (* equal contribution, # corresponding author)
International Conference on Learning Representations (ICLR) 2026
Large language models (LLMs) have recently achieved impressive performance across a wide range of natural language tasks and are now widely used in real-world applications. Among them, black-box LLMs--served via APIs without access to model internals--are especially dominant due to their scalability and ease of deployment. Despite their strong capabilities, these models typically produce generalized responses that overlook personal preferences and reasoning styles. This has led to growing interest in black-box LLM personalization, which aims to tailor model outputs to user-specific context without modifying model parameters. However, existing approaches primarily focus on response-level personalization, attempting to match final outputs without modeling personal thought process. To address this limitation, we propose RPM, a framework for reasoning-level personalization that aligns the model's reasoning process with a user's personalized logic. RPM first constructs statistical user-specific factors by extracting and grouping response-influential features from user history. It then builds personalized reasoning paths that reflect how these factors are used in context. In the inference stage, RPM retrieves reasoning-aligned examples for new queries via feature-level similarity and performs inference conditioned on the structured factors and retrieved reasoning paths, enabling the model to follow user-specific reasoning trajectories. This reasoning-level personalization enhances both predictive accuracy and interpretability by grounding model outputs in user-specific logic through structured information. Extensive experiments across diverse tasks show that RPM consistently outperforms response-level personalization methods, demonstrating the effectiveness of reasoning-level personalization in black-box LLMs.

Review-driven Personalized Preference Reasoning with Large Language Models for Recommendation
Jieyong Kim*, Hyunseo Kim*, Hyunjin Cho, SeongKu Kang, Buru Chang, Jinyoung Yeo, Dongha Lee# (* equal contribution, # corresponding author)
Special Interest Group on Information Retrieval (SIGIR) 2025
Recent advancements in Large Language Models (LLMs) have demonstrated exceptional performance across a wide range of tasks, generating significant interest in their application to recommendation systems. However, existing methods have not fully capitalized on the potential of LLMs, often constrained by limited input information or failing to fully utilize their advanced reasoning capabilities. To address these limitations, we introduce EXP3RT, a novel LLM-based recommender designed to leverage rich preference information contained in user and item reviews. EXP3RT is basically fine-tuned through distillation from a teacher LLM to perform three key tasks in order: EXP3RT first extracts and encapsulates essential subjective preferences from raw reviews, aggregates and summarizes them according to specific criteria to create user and item profiles. It then generates detailed step-by-step reasoning followed by predicted rating, i.e., reasoning-enhanced rating prediction, by considering both subjective and objective information from user/item profiles and item descriptions. This personalized preference reasoning from EXP3RT enhances rating prediction accuracy and also provides faithful and reasonable explanations for recommendation. Extensive experiments show that EXP3RT outperforms existing methods on both rating prediction and candidate item reranking for top-k recommendation, while significantly enhancing the explainability of recommendation systems.
Review-driven Personalized Preference Reasoning with Large Language Models for Recommendation
Jieyong Kim*, Hyunseo Kim*, Hyunjin Cho, SeongKu Kang, Buru Chang, Jinyoung Yeo, Dongha Lee# (* equal contribution, # corresponding author)
Special Interest Group on Information Retrieval (SIGIR) 2025
Recent advancements in Large Language Models (LLMs) have demonstrated exceptional performance across a wide range of tasks, generating significant interest in their application to recommendation systems. However, existing methods have not fully capitalized on the potential of LLMs, often constrained by limited input information or failing to fully utilize their advanced reasoning capabilities. To address these limitations, we introduce EXP3RT, a novel LLM-based recommender designed to leverage rich preference information contained in user and item reviews. EXP3RT is basically fine-tuned through distillation from a teacher LLM to perform three key tasks in order: EXP3RT first extracts and encapsulates essential subjective preferences from raw reviews, aggregates and summarizes them according to specific criteria to create user and item profiles. It then generates detailed step-by-step reasoning followed by predicted rating, i.e., reasoning-enhanced rating prediction, by considering both subjective and objective information from user/item profiles and item descriptions. This personalized preference reasoning from EXP3RT enhances rating prediction accuracy and also provides faithful and reasonable explanations for recommendation. Extensive experiments show that EXP3RT outperforms existing methods on both rating prediction and candidate item reranking for top-k recommendation, while significantly enhancing the explainability of recommendation systems.
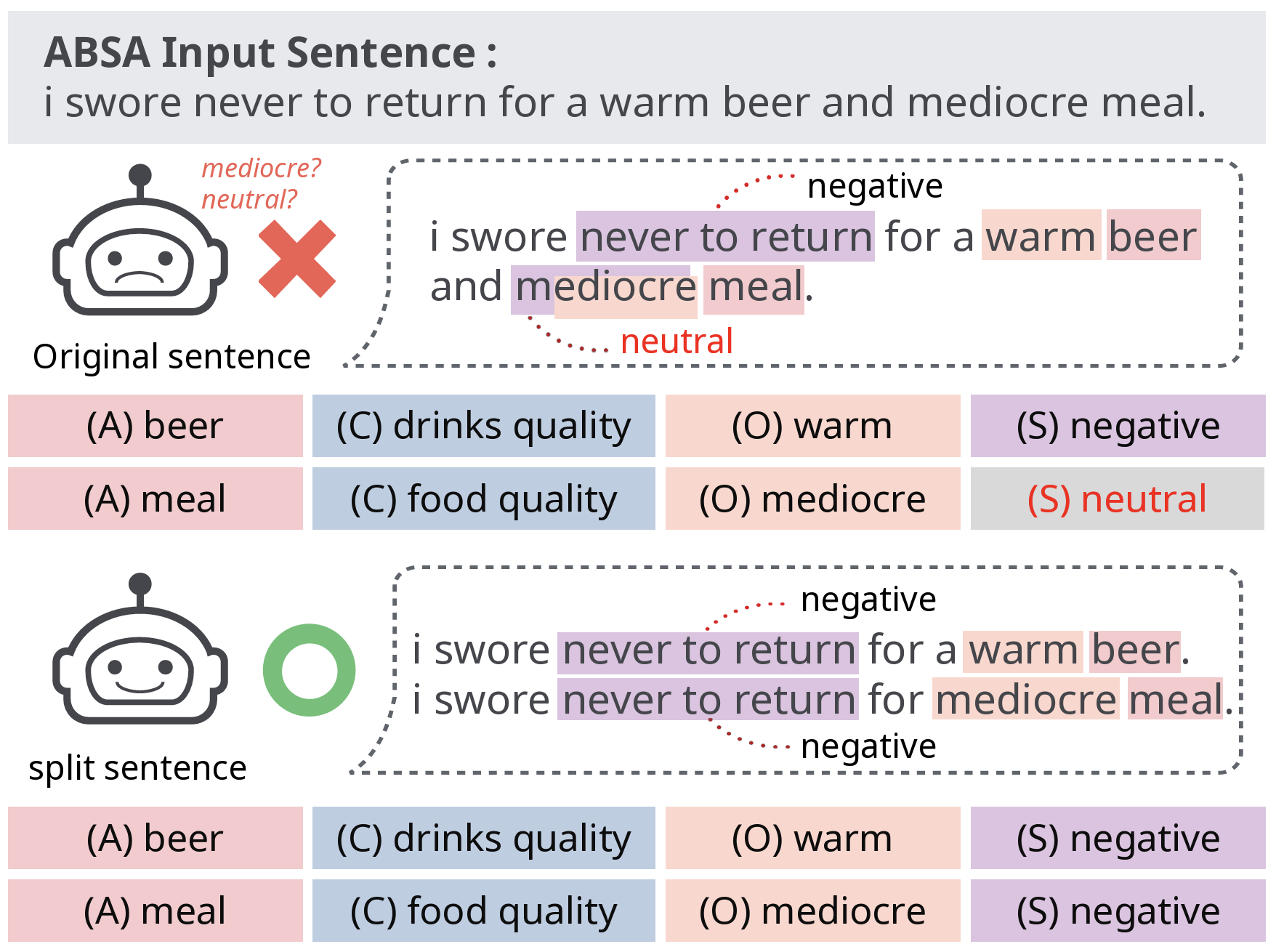
Make Compound Sentences Simple to Analyze: Learning to Split Sentences for Aspect-based Sentiment Analysis
Yongsik Seo*, Sungwon Song*, Ryang Heo*, Jieyong Kim, Dongha Lee# (* equal contribution, # corresponding author)
Conference on Empirical Methods in Natural Language Processing (EMNLP) Findings 2024
In the domain of Aspect-Based Sentiment Analysis (ABSA), generative methods have shown promising results and achieved substantial advancements. However, despite these advancements, the tasks of extracting sentiment quadruplets, which capture the nuanced sentiment expressions within a sentence, remain significant challenges. In particular, compound sentences can potentially contain multiple quadruplets, making the extraction task increasingly difficult as sentence complexity grows. To address this issue, we are focusing on simplifying sentence structures to facilitate the easier recognition of these elements and crafting a model that integrates seamlessly with various ABSA tasks. In this paper, we propose Aspect Term Oriented Sentence Splitter (ATOSS), which simplifies compound sentence into simpler and clearer forms, thereby clarifying their structure and intent. As a plug-and-play module, this approach retains the parameters of the ABSA model while making it easier to identify essential intent within input sentences. Extensive experimental results show that utilizing ATOSS outperforms existing methods in both ASQP and ACOS tasks, which are the primary tasks for extracting sentiment quadruplets.
Make Compound Sentences Simple to Analyze: Learning to Split Sentences for Aspect-based Sentiment Analysis
Yongsik Seo*, Sungwon Song*, Ryang Heo*, Jieyong Kim, Dongha Lee# (* equal contribution, # corresponding author)
Conference on Empirical Methods in Natural Language Processing (EMNLP) Findings 2024
In the domain of Aspect-Based Sentiment Analysis (ABSA), generative methods have shown promising results and achieved substantial advancements. However, despite these advancements, the tasks of extracting sentiment quadruplets, which capture the nuanced sentiment expressions within a sentence, remain significant challenges. In particular, compound sentences can potentially contain multiple quadruplets, making the extraction task increasingly difficult as sentence complexity grows. To address this issue, we are focusing on simplifying sentence structures to facilitate the easier recognition of these elements and crafting a model that integrates seamlessly with various ABSA tasks. In this paper, we propose Aspect Term Oriented Sentence Splitter (ATOSS), which simplifies compound sentence into simpler and clearer forms, thereby clarifying their structure and intent. As a plug-and-play module, this approach retains the parameters of the ABSA model while making it easier to identify essential intent within input sentences. Extensive experimental results show that utilizing ATOSS outperforms existing methods in both ASQP and ACOS tasks, which are the primary tasks for extracting sentiment quadruplets.
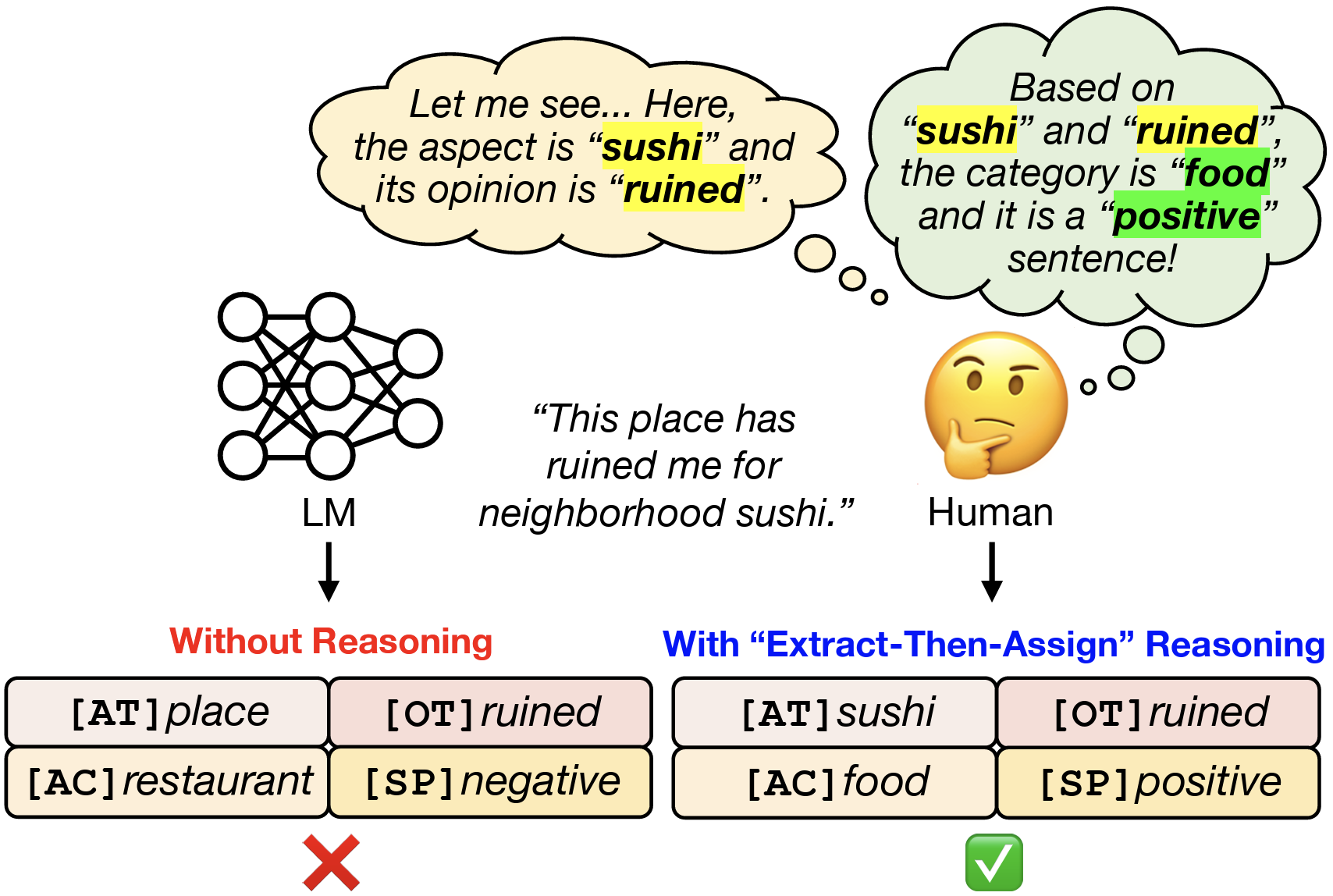
Self-Consistent Reasoning-based Aspect-Sentiment Quad Prediction with Extract-Then-Assign Strategy
Jieyong Kim*, Ryang Heo*, Yongsik Seo, SeongKu Kang, Jinyoung Yeo, Dongha Lee# (* equal contribution, # corresponding author)
Annual Meeting of the Association for Computational Linguistics (ACL) Findings 2024
In the task of aspect sentiment quad prediction (ASQP), generative methods for predicting sentiment quads have shown promising results. However, they still suffer from imprecise predictions and limited interpretability, caused by data scarcity and inadequate modeling of the quadruplet composition process. In this paper, we propose Self-Consistent Reasoning-based Aspect-sentiment quadruple Prediction (SCRAP), optimizing its model to generate reasonings and the corresponding sentiment quadruplets in sequence. SCRAP adopts the Extract-Then-Assign reasoning strategy, which closely mimics human cognition. In the end, SCRAP significantly improves the model's ability to handle complex reasoning tasks and correctly predict quadruplets through consistency voting, resulting in enhanced interpretability and accuracy in ASQP.
Self-Consistent Reasoning-based Aspect-Sentiment Quad Prediction with Extract-Then-Assign Strategy
Jieyong Kim*, Ryang Heo*, Yongsik Seo, SeongKu Kang, Jinyoung Yeo, Dongha Lee# (* equal contribution, # corresponding author)
Annual Meeting of the Association for Computational Linguistics (ACL) Findings 2024
In the task of aspect sentiment quad prediction (ASQP), generative methods for predicting sentiment quads have shown promising results. However, they still suffer from imprecise predictions and limited interpretability, caused by data scarcity and inadequate modeling of the quadruplet composition process. In this paper, we propose Self-Consistent Reasoning-based Aspect-sentiment quadruple Prediction (SCRAP), optimizing its model to generate reasonings and the corresponding sentiment quadruplets in sequence. SCRAP adopts the Extract-Then-Assign reasoning strategy, which closely mimics human cognition. In the end, SCRAP significantly improves the model's ability to handle complex reasoning tasks and correctly predict quadruplets through consistency voting, resulting in enhanced interpretability and accuracy in ASQP.